企业监控平台建设-需求分析篇
前言
工作以来一直在做监控平台相关的工作,最近计划写一系列文章总结下对企业监控平台建设的思考,本文是第一篇
- 需求分析
- 产品设计
- 架构设计
- 模块设计
- 运维
- 运营
下面开始正文
确定目标
在做任何事情的之前,我们要先思考做这件事情的意义和价值。企业为什么需要监控平台呢?公司的首要目标是创造利润,创造利润的前提的是保证服务的运转正常。
监控就是保证服务正常运行的一个手段。如果把公司运行比作一辆正在奔跑的汽车,那监控系统就好比汽车上的仪表盘。没了仪表盘汽车跑起来的后果大家可想而知。
所以我们建设监控平台的目标是 保障线上服务的稳定性 让业务正常运转给公司不断创建利润
目标拆解
既然监控平台的目标是保障线上服务的稳定性,所以我们的关注的对象是线上服务 ,我们要到达的效果是使其稳定运行 。
所以我们先以线上服务为中心,对应用的上下游以及依赖资源进行梳理,下面是一个线上服务典型的架构

对上线服务有所了解后,那我们就从保证服务稳定性的四板斧来思考监控系统建设,四板斧是什么呢?答案如下
- 避免故障发生(预防)
- 故障发生及时感知(发现)
- 故障发生及时定位(定位)
- 故障发生及时将其消除(止损)
上面四个抓手都提到了故障,那我们就先分析一下,都有哪些原因会引发故障,根据以往经验,主要有一下几类
- 变更
- 基础资源不足
- 代码缺陷
- 第三方依赖
- …
对服务对象和故障分类都有一定了解后,我们开始梳理产品需求,产品需求都是为了解决某个场景下的问题而产生的,下面我们就根据上文提到的保障稳定性的四个抓手,来看看对于监控平台而言都有哪些诉求
避免故障发生(预防)
根据墨菲定律,可能发生的事情就一定会发生,所以线上服务是一定会发生故障的,但我们可以降低故障发生的概率,根据对故障分类的分析,我们了解到,当基础资源容量不足时,也会导致触发故障,资源资源的消耗都有一个增长的过程,所以此类故障是可以提前发现,并规避的。 因此,为了避免故障的发生,我们要对上线服务依赖的所有基础资源使用情况进行监控,包括但不限于
- 机器基础资源(cpu mem disk io net)
- 网络带宽
- 数据库
- 消息队列
- 存储服务
所以,我们的监控平台就有了第一个需求,对基础资源的用量做采集,并在用尽之前收到发出预警。
故障发生及时感知(发现)
从优先级来说,在监控能力完全没有的情况下,优先级最高的是故障发生时立即感知,尤其是影响核心业务的故障,那如何做到这一点呢,首先对业务的核心数据进行梳理,对百度来说是广告收入,对滴滴来说是呼叫量和应答量,所以第一步我们要做是确定核心业务数据,对业务数据进行采集,并当核心业务数据异常时立即感知。
一个业务线往往是由很多个模块组成的,如果某一个模块故障,也可能会影响整个业务的,所以某个模块发生故障,我们也要及时感知,那如何确定一个模块是否有问题呢?可以用《google sre》中提到的黄金三指标来做判断,QPS、延迟和错误率 ,QPS、延迟和错误率升高往往是一个模块出现问题的前兆。为了感知这个情况,所以监控平台要有对各个模块接口的QPS,延迟,错误率进行采集的能力,当模块某个接口这三个指标出现故障时,及时感知
每一个模块都是由一个或多个程序实例组成,如果模块程序是部署在物理机器上的,如果机器出现故障,模块本身也可能会受到影响,那么如果判断一个机器是否出现问题呢,看他的物理资源,CPU、内存耗尽,磁盘、网卡打满,磁盘不可读写,机器死机,磁盘网卡故障,所以我们要对模块所在物理机是否异常进行监控,在物理机故障时能要及时感知并预警。此外如果进程本身panic了,模块服务也会受影响,所以进程意外退出,也要及时感知和预警
此外,从用户发起请求到最后收到响应,整个信息都是依靠网络传输的,任何一个环节的网络出现问题,都可能导致用户的服务不能正常使用,所有我们要对整理传输链路依赖的网络进行监控,下面我们对一个请求从用户发起到用户最后收到响应,整个过程进行一次梳理,如下图
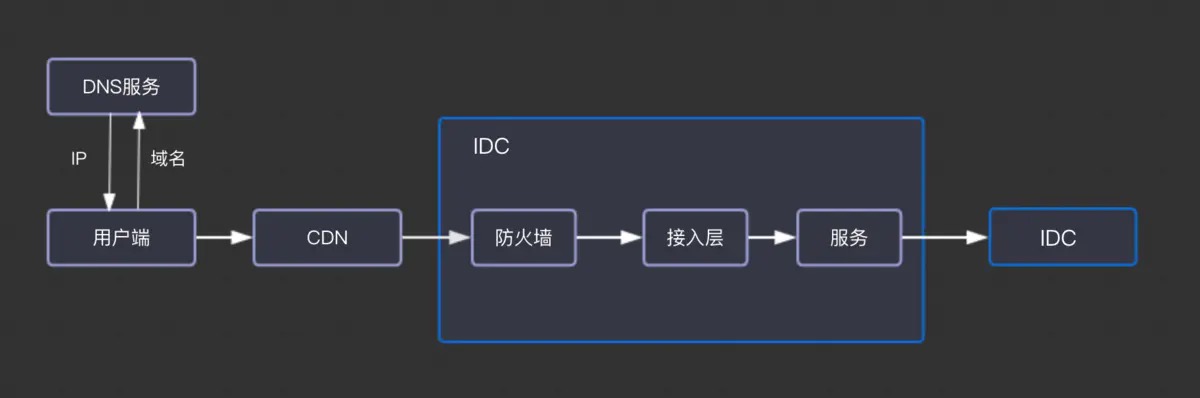
从上图可以看出,为了做的网络故障时我们能及时感知,要对以下几个环节的网络质量进行数据采集
- 域名解析成功率
- 用户端到端网络访问质量
- 内网传输
- 专线传输
当核心接口的QPS下降之后,如果后端模块均正常,那有可能是网络问题,也有可能是用户端测的程序出现了问题,所以也要对用户端程序的异常事件进行采集,大量异常是及时感知并预警
故障发生及时定位(定位)
故障发生之后,如果监控覆盖度足够高,会收到告警提醒,但如果是一个业务出现问题,收到的告警可能只是表面原因,不一定是root case,导致故障的原因可能有很多种,我们如何快速定位哪个是root case,这个是监控系统需要做的事情,根据对历史故障的分析总结,导致故障原因次数最多的是线上变更,所以我们要对线上的变更事件进行收集并统一展示,以此来快速确认故障是否是线上变更导致的
排除变更影响后,我们一般从两个思路逐个排查
从全局到局部的思路排查
- 首先确认哪个业务场景有问题,因此监控系统需要提供快速查看全局核心业务场景是否异常以及影响面有多大的能力
- 当确认某个业务场景异常后,我们需要快速知道是哪个模块异常引起的,所以监控系统要提供快速查看某个业务场景所有模块是否异常的能力,通过成功率、QPS、延迟来体现
- 定位到模块级别之后 3.1 快速查看模块自身服务是否正常,模块自身相关的报警有哪些,可以展示到卡片上,看图和告警联动更紧密一下 3.2 快速查看依赖的基础资源是否异常 3.3 快速查看其依赖的下游模块是否异常
- 查看用户端侧整体可用性、报错率是否异常
从网络传输的思路排查
- 查看用户端访问的服务核心域名是否正常
- 查看用户访问cdn资源是否异常
- 用户端到idc服务的整体访问质量
- idc内部交换机网络是否正
- idc专线是否正常
通过上面的梳理,我们发现当故障发生时,我们需要确认的事情非常之多,这个过程也会消耗很大时间,有什么解决办法么,有一个思路是故障定位自动化,根据已知的所有事件,自动推荐出最有可能的root case,这个也是监控平台未来的一个发展方向
故障后及时将其消除(止损)
故障发生后我们立即要做的其实止损,而不是定位,如果止损动是人工来操作,从收到告警到开始处理,往往会浪费很多时间,因为监控平台要提供一种告警发生(根因明确)后,能够联动其他系统进行自动治愈故障的能力 ,这样可以大大减少故障的时间,也可以很大的节省人力成本。
总结
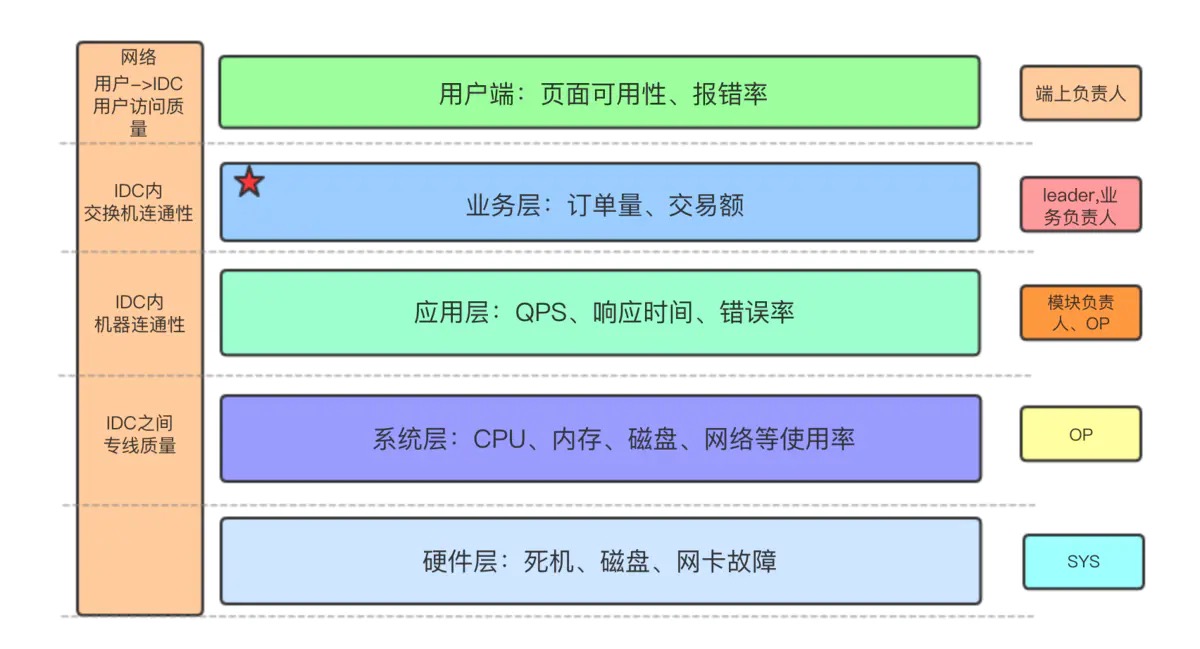
从稳定性的四个抓手,我们梳理出一些表征业务稳定性的关键指标,总结成一张图如下
通过对以上需要的分析整理,我们可以抽象出监控平台需要提供的三大功能
- 数据采集
- 报警
- 数据展示
下面用一个脑图将三大功能和实际需求对应起来

本文从考虑稳定性的视角出发,对监控系统的实际需求进行了整体的总结和梳理,第二篇我们将对这些需求进行抽象,来思考如何设计一款简单易用的监控产品
Changelog
- 20190629:秦叶宁创建
- 原文作者:秦叶宁
- 原文链接:http://www.qinyening.com/post/2019-06-29-monitor01/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。